
Lessons Learned From Fuzzing Centrifuge Protocol Part 1
Key takeaways from our engagement with Centrifuge

Overview
Recently the Centrifuge Protocol team engaged the Recon team to implement a fuzz testing suite in their system. The engagement was conducted over three weeks and split into two phases.
We started by running the Centrifuge team through our invariant writing workshop where we guided them through the process of using their knowledge of the system to specify its invariants.
As the primary objective of this first phase was to achieve high line coverage of the contracts in-scope, the faster (experimental) Medusa fuzzer helped us implement shorter iteration cycles for expanding coverage on the properties defined in the workshop.
We then switched to more accurate longer runs, done with Echidna in the second phase of the engagement. These longer duration runs were performed using the Recon Pro Jobs feature which allowed the team to run multiple jobs on a cloud service in parallel without having to allocate computational resources on a personal machine.
In this post we’ll look at this first phase of the engagement to see some useful insights regarding testing approaches for achieving high coverage as well as an innovative method for introducing extra randomness into the system via the fuzzer to allow testing a greater number of possible system states.
An introduction to Centrifuge
Centrifuge is a Real World Asset (RWA) lending protocol. Centrifuge’s Liquidity Pools allow deployment of Centrifuge RWA pools on any EVM-compatible blockchain. RWA pools permit investors to provide liquidity based on their appetite for risk via tranches, where each tranche is defined by a separate LiquidityPool and TrancheToken.
Each TrancheToken can have multiple underlying assets backing it, therefore the relationship between underlying assets to RWA pools is many-to-many, as shown in the diagram below.
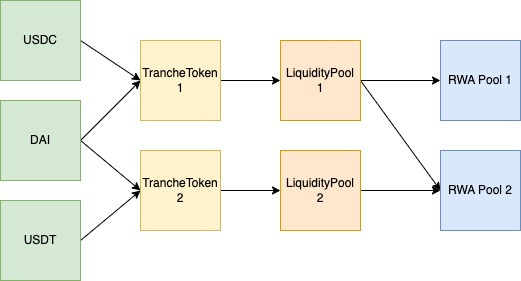
LiquidityPools in Centrifuge implement the ERC-7540 (an extension of ERC-4626 vaults) standard which allows investors to deposit stablecoins as the underlying asset and receive shares of the pool in the form of TrancheTokens.
The Centrifuge chain is a separate trusted chain that creates a bridge to the RWA pools from the LiquidityPools on Ethereum and processes investor actions (depositing, withdrawing, etc.) taken on the Ethereum side.

In this review only the Manager and Liquidity Pool contracts in the above image were of interest because the Gateway + Routers were determined to work more as handlers/filters to messages of the rest of the system and therefore wouldn’t provide interesting results to apply fuzzing to (see takeaway 2).
A Novel Approach to Expand Coverage
Achieving high coverage is the ultimate goal of any fuzzing campaign, but the mechanisms by which it’s achieved determines if all possible code paths in the system have been explored, or if only a small subset of these paths were explored.
As we’ll see below, the ability to have multiple contract implementations with different configurations introduces new possible paths that forces us to expand our definition of coverage to include not only line coverage but possible contract implementation combinations as well.
Now we’ll look at the three primary takeaways from this engagement and how they can help you achieve meaningful coverage in your own project.
Takeaways
1. Reuse first, abstract later
When first setting up a fuzzing campaign achieving coverage of stateful fuzz tests over the majority of target contracts is usually a good first objective. When creating an implementation of the desired property being tested it usually includes calls to the target contract to fetch state variable values to check pre/postconditions.
Running these tests for a brief period of time then allows you to discover any local maxima being reached by the fuzzer, places where calls by the fuzzer are always reverting, causing coverage to not expand beyond a given percentage.
This is where initially being verbose in the setup code for such tests can be helpful as it allows visualizing the exact location where reverts are occurring. Abstracting away shared logic required for test setup too early can make debugging much more difficult as a function implementation used to reduce repeated logic may be called by multiple target paths.
Looking at an example made to highlight this from the target functions of the LiquidityPool contract we can see this in practice:
function liquidityPool_redeem(uint256 shares) public {
...
uint256 tokenUserB4 = token.getBalance(actor, true);
...
}function liquidityPool_withdraw(uint256 assets) public {
...
uint256 tokenUserB4 = token.getBalance(actor, false);
...
}We see that these both define a tokenUserB4 variable that loads a user’s balance by making a call to the token::getBalance function and with this implementation we can see in the initial coverage report where one of the calls reverts:

Since this logic is repeated for both functions it could easily be abstracted into an internal function that would simplify the code and make it easier to read, which might look like:
function _getActorBalance(address actor) internal {
uint256 tokenUserB4 = token.getBalance(address(actor), false);
}but as was mentioned above this can complicate things when initially trying to expand coverage for the fuzzer as the coverage report will show the function highlighted in green but also having reverted:

This makes it difficult to determine in which path the function has reverted (was it the call in liquidityPool_redeem or liquidityPool_withdraw), requiring isolating the target functions or using try/catch blocks, which slows down the coverage expanding process.
2. Only fuzz what’s necessary
In Centrifuge’s architecture, messages are processed on the Centrifuge chain and then handled on Ethereum by a set of receiving contracts (Gateway and Routers).
It was determined in this phase of the engagement that fuzzing the message creators from the Centrifuge chain themselves wouldn’t actually be beneficial as it adds significant overhead in terms of test setup and computation and would fundamentally act as a barrier to testing the behavior on the EVM side of the protocol.
The following image shows the result of these decisions in aggregate, allowing the system to be tested in a simplified manner.

While the logic of the Gateway and Router contracts were excluded, the potential extra randomness introduced by calls to permissioned functions in them via messages from Centrifuge that modify the global state of the system (things like pausing/unpausing, disabling certain tokens to be used in the liquidity pools, etc.) were maintained as target functions in a GatewayMock contract. This helped maintain a high number of possible combinations on the system, ensuring that invariants hold on all of them without introducing unnecessary computational overhead for the fuzzer.
3. Add extra randomness by fuzzing setup
Fundamentally the targets of the fuzzer were the LiquidityPool, PoolManager and InvestmentManager contracts, however because the LiquidityPool contracts can exist in the system with multiple instances, with multiple underlying assets backing their associated TrancheTokens, a mechanism was needed to enable examining cases where different configurations of this contract could be tested to ensure they all behaved as expected.
From a high level the problem was how to effectively explore the set of all possible ERC20(asset) + TrancheToken + LiquidityPool combinations without requiring each to be hardcoded.
This is where the fuzzer was used to introduce randomness by creating target functions that performed deployment steps for deploying multiple such combinations of contracts. This essentially copies actions that would normally be performed in a test setup function where values would be deterministically hardcoded and instead uses nondeterministic fuzzed values to create more possible combinations with minimal additional computational overhead.
The implementation used to achieve this was done through the following deployNewTokenPoolAndTranche function which as it states deploys a new TrancheToken and associated LiquidityPool.
function deployNewTokenPoolAndTranche(uint8 decimals, uint256 initialMintPerUsers) public returns (address newToken, address newTrancheToken, address newLiquidityPool)
{
// NOTE: TEMPORARY
require(!hasDoneADeploy); // This bricks the function for this one for Medusa
// Meaning we only deploy one token, one Pool, one tranche
if (RECON_USE_SINGLE_DEPLOY) {
hasDoneADeploy = true;
}
if (RECON_USE_HARDCODED_DECIMALS) {
decimals = 18;
}
initialMintPerUsers = 1_000_000e18;
// NOTE END TEMPORARY
newToken = addToken(decimals, initialMintPerUsers);
{
CURRENCY_ID += 1;
poolManager_addCurrency(CURRENCY_ID, address(newToken));
}
{
POOL_ID += 1;
poolManager_addPool(POOL_ID);
poolManager_allowInvestmentCurrency(POOL_ID, CURRENCY_ID);
}
{
string memory name = "Tranche";
string memory symbol = "T1";
poolManager_addTranche(POOL_ID, TRANCHE_ID, name, symbol, 18, 2);
}
newTrancheToken = poolManager_deployTranche(POOL_ID, TRANCHE_ID);
newLiquidityPool = poolManager_deployLiquidityPool(POOL_ID, TRANCHE_ID, address(newToken));
// NOTE: This sets the actors
// We will cycle them through other means
// NOTE: These are all tightly coupled
// First step of uncoupling is to simply store all of them as a setting
// So we can have multi deploys
// And do parallel checks
// O(n)
// Basically switch on new deploy
// And track all historical
// O(n*m)
// Second Step is to store permutations
// Which means we have to switch on all permutations on all checks
liquidityPool = LiquidityPool(newLiquidityPool);
token = ERC20(newToken);
trancheToken = TrancheToken(newTrancheToken);
restrictionManager = RestrictionManager(address(trancheToken.restrictionManager()));
trancheId = TRANCHE_ID;
poolId = POOL_ID;
currencyId = CURRENCY_ID;
// NOTE: Implicit return
}This allows the number of actors in the system to be toggled by the fuzzer. The implications of such a setup are profound as it not only allows multiple pools and multiple token deployments, but also scenarios that might otherwise be overlooked such as implementations where pools use asset tokens of different decimal values.
We can see how this increases the possible states in the following diagram:
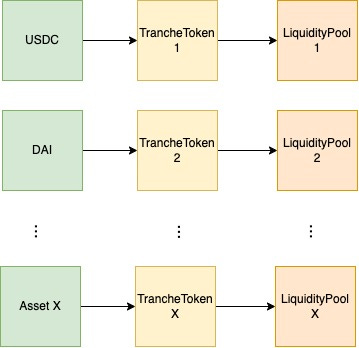
deployNewTokenPoolAndTranche allows us to deploy multiple combinations of Asset + TrancheToken + LiquidityPool contracts.This mechanism essentially broadens the search space for potential bugs by orders of magnitude in a way that wouldn’t be possible with just using a traditional setup function to deploy all the contracts of interest. Ideally, this creates a new dimension of coverage where one can have a greater certainty that all code paths were reached not only in one system configuration, but a large majority of all possible configurations.
Exposing a switchLiquidityPool function then allows the fuzzer to change the system configuration with a single call:
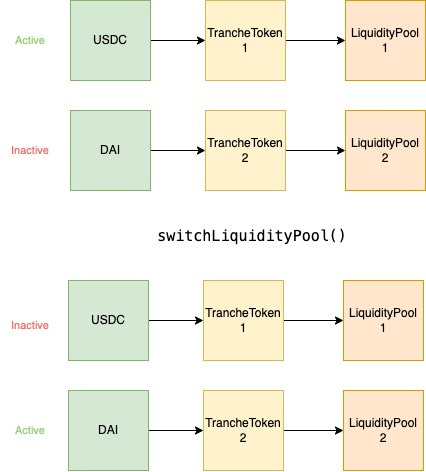
switchLiquidityPool changes the system configuration.Conclusion
In this first post, we’ve explored multiple strategies to make coding invariant tests simple and effective.
In the next post we’ll look at how broken properties from the tests implemented in this phase were evaluated to determine if they were valid bugs or identified valid issues that were non-exploitable. Additional properties that could not be tested with stateful fuzz tests were also defined as invariant tests and evaluated during this second phase.
If you've made it this far you value the security of your protocol.
At Recon we offer boutique audits powered by invariant testing. With this you get the best of both worlds, a security audit done by an elite researcher paired with a cutting edge invariant testing suite.
Sound interesting? Reach out to us here:
