
Introducing Recon Magic
Writing Stateful Fuzzing 38 times faster using Agentic Workflows - Benchmark inside


Introduction
In this post we outline a standardized way to evaluate meaningful line coverage for smart contract fuzzing, what we’ve termed standardized line coverage.
We then detail how we’ve used this as the optimization function in the implementation of Recon Magic, an agentic workflow that can achieve high standardized line coverage over any production smart contract system written in Solidity.
We believe the improvements demonstrated below represent a significant shift in the ability to implement stateful fuzzing in smart contract systems, making it multiple times faster and therefore more practical for widespread use.
Standardized Line Coverage
Line coverage in the context of stateful fuzzing is defined as the lines in a given contract that a test suite with a given configuration is able to reach over the course of a fuzzing campaign.
While testing a system using stateful fuzzing, we can define a subset of all the functions in a contract as functions that are of interest. This subset is what allows the fuzzer to actually explore the possible system states. When using Recon’s Chimera framework, this subset is reachable only by the functions defined in or inherited by the TargetFunctions contract. Additional functions of interest are those called as internal functions or via external calls by the target functions.
Given that our goal is to test all possible smart contract state combinations, we need a way to extract and classify only the coverage over the functions of interest to us. This has motivated us to create a new subcategory which we have termed standardized line coverage which classifies the line coverage of a smart contract after having removed all lines not of interest contributed by view/pure functions and uncalled functions.
The current tooling used for stateful fuzzing (namely Echidna, Medusa and Foundry) incorporate the full set of all functions in a given targeted contract into the coverage reports they generate. As a result, view, pure and unused functions are included in the overall calculation of a contract’s coverage:
Standardized line coverage defines the subset of these functions as those that can alter a system’s state, which are what get targeted by the fuzzer in order to explore meaningful combinations. This includes not only the top level target functions but any functions that appear in the target function’s call trace which may include internal functions, external contract calls and library functions.
With this definition in place, we can say that reaching standardized line coverage is a better metric for indicating that the fuzzer has reached 100% line coverage (see future work for a better metric).
An Agentic Workflow
Creating a test suite that reaches standardized line coverage is a nontrivial task. The primary difficulty comes in creating the test scaffolding that defines the subset of functions to be called and ensuring that the fuzzer can easily reach all possible paths within these functions. Traditionally this has required many hours of work and an iterative cycle of writing the test suite, running the fuzzer, then reevaluating to determine if coverage improved with the latest changes.
Given that this is a repetitive task that follows certain heuristics, it makes it ideal for the application of an agentic AI workflow to speed up the process.
Recently, we set out to create such an agentic workflow with the following points to benchmark the quality of the output of the workflow against:
High (ideally full) standardized line coverage
Code can be easily maintained
Code mirrors what an experienced engineer would write
Avoids introducing test suite bugs (bias, wrong assumptions and common mistakes)
Achieving standardized line coverage is the primary objective function of the agentic workflow, where the other points are meant to guide the agent in how it achieves this.
To ensure that the written code was of high quality and easy to maintain, we set constraints on the agent so that it would implement the suite using the following best practices:
Create clamped handlers by calling the unclamped handler, creating a subset of the input space, while allowing the fuzzer to explore the rest of the state space through the unclamped handler.
Input values for clamped handlers were clamped using dynamic system state values or static values from the test suite setup.
Implement shortcut functions (functions which make calls to multiple handlers) which allow exploring states that might be hard to reach if solely relying on random calls by the fuzzer.
If the code compiles with Foundry it will be runnable by Echidna and Medusa.
An additional implicit requirement is that the workflow would use our Chimera framework by default to create the test suite, as it already handles many design decisions that the agent would otherwise have to make itself.
The Chimera framework is discussed in depth in the Recon Book. We believe there is sufficient precedence for using it as it’s one of the most widely used fuzzing frameworks, as can be seen in this list of public fuzzing campaigns. Additionally, the extension we created which uses the framework by default has over 700 downloads.
Below we share the results of the created workflow which deterministically follows these guiding principles and in the vast majority of cases, the AI Workflow generates a test suite that is not just usable, but also very similar if not identical to how Recon engineers would write it. More importantly, it systematically achieves high standardized line coverage for any project.
Methodology
The methodology used by the Recon Magic agentic workflow centers around the implementation of clamped handlers and shortcut functions.
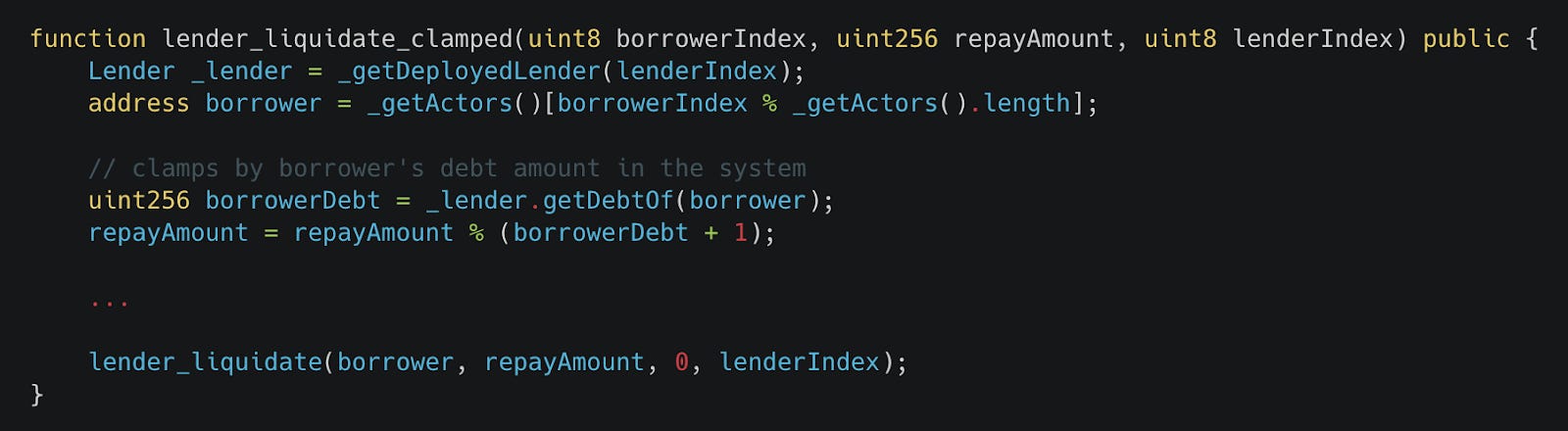
Clamped Handlers
Clamped handlers reduce the search space for a given function by restricting the input values. Effective clamping strategies for clamped handlers broadly fall into one of two categories:
Using values from the test suite setup to restrict inputs

Using values from the system state to restrict inputs
Shortcut Functions
Shortcut functions are similar to clamped handlers in that they allow greater state exploration. However, instead of including only one state changing function call, shortcut functions combine multiple state changing function calls into a single function:
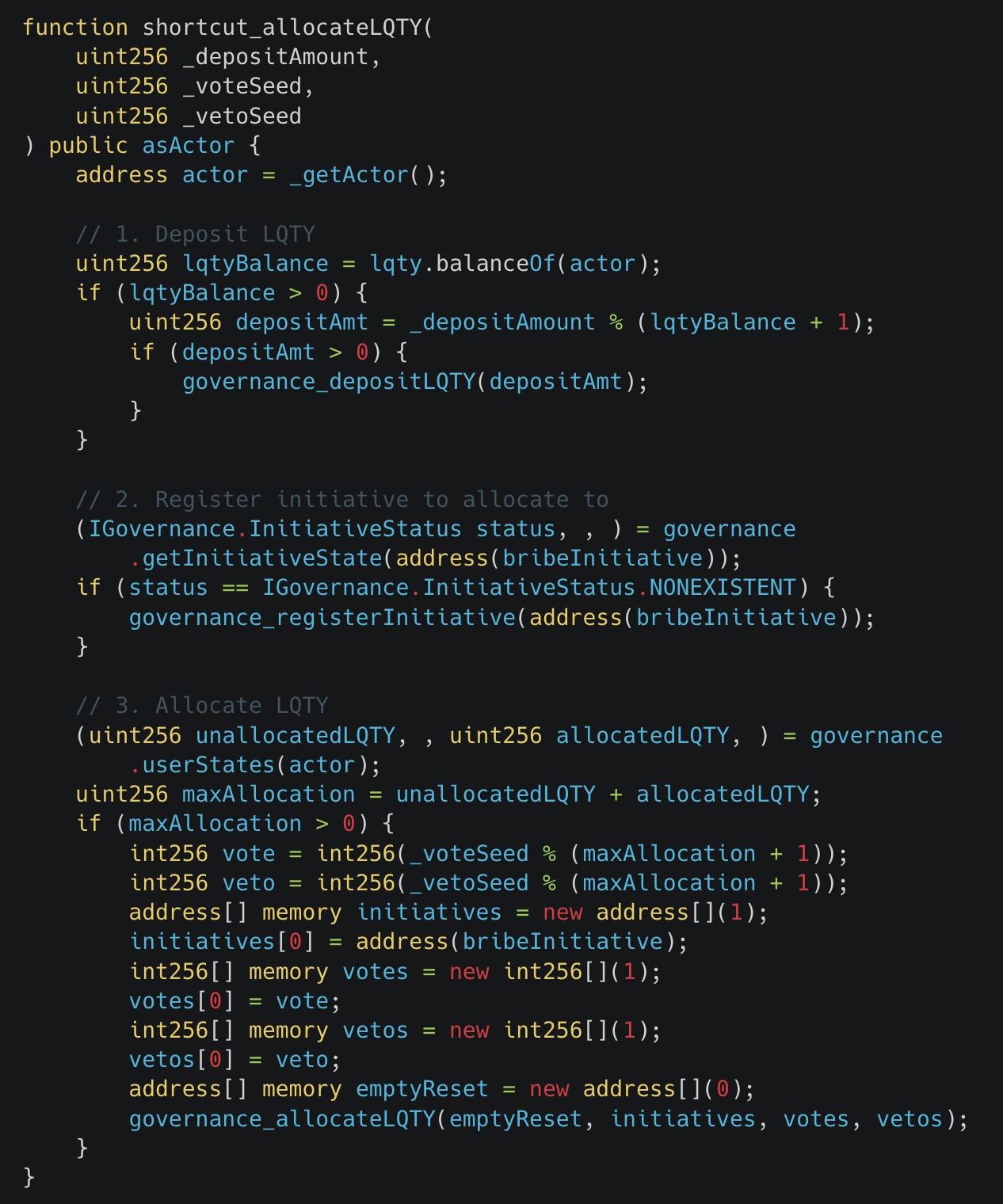
This allows the fuzzer to explore deep state transitions that may take significantly longer to be achieved if called via individual handlers.
Evaluation
To evaluate the efficacy of our workflow, we compared the standardized line coverage of two different test cases (unclamped handlers versus clamped handlers and shortcuts) after a 4 hour fuzzing run.
Both test cases start with setups which deploy the system in an effective manner that makes it possible for the fuzzer to explore all meaningful states. The version with unclamped target functions then runs the fuzzer directly on this setup without reducing the search space of any of the target functions with clamping (the control case). The version with the clamped target functions has had the workflow run on it (the experimental group) to apply clamping as well as implementing shortcut functions.
This test was performed on 5 different real-world codebases (Liquity Governance V2, Superform Periphery V2, Monolith, AAVE V4 and Nerite).
Results
The average run of Recon Magic takes about 2-3 hours to achieve high standardized line coverage (depending on the complexity of the codebase), which would previously take an average of 3-5 days for a human engineer, a 38x increase in efficiency (average 96 hours before vs 2.5 hours now).
The following benchmarks comparing the standardized line coverage of the control suite and the experimental suite were performed with a run of Echidna in assertion mode for 4 hours on the Recon cloud runner. The results are shown below (links to each of the runs are provided in the image caption):
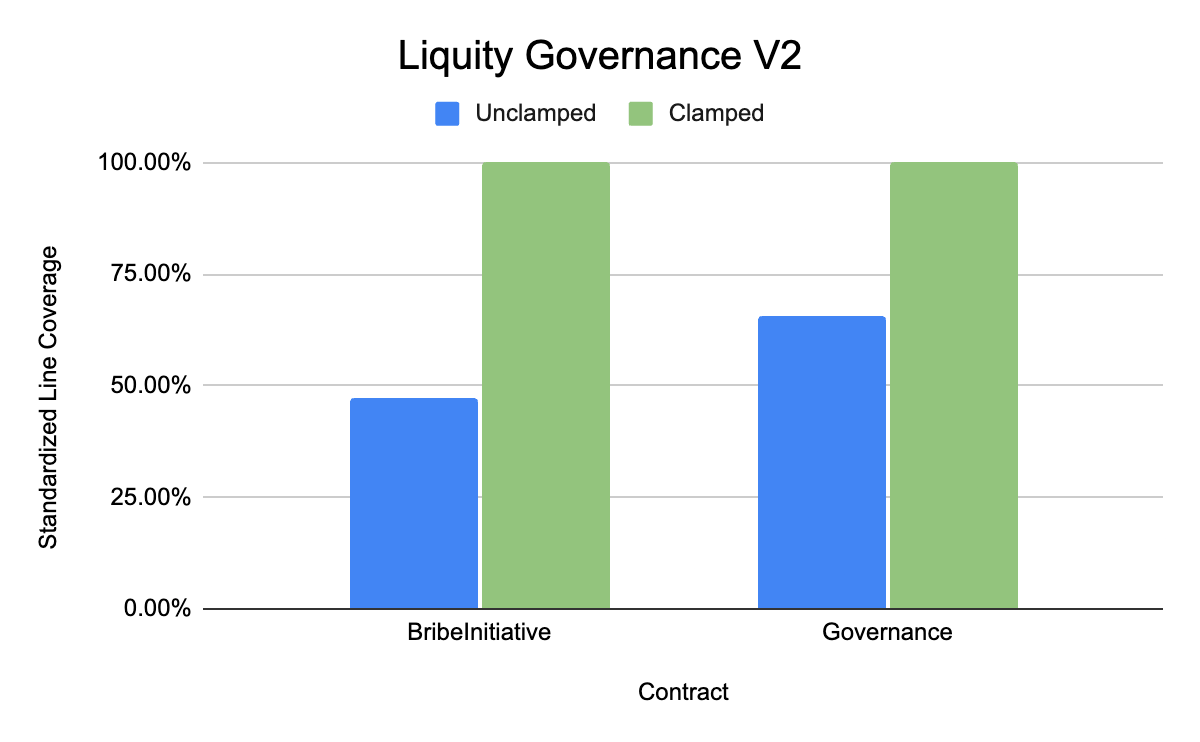
Liquity Governance V2 (core contracts of interest are BribeInitiative and Governance)
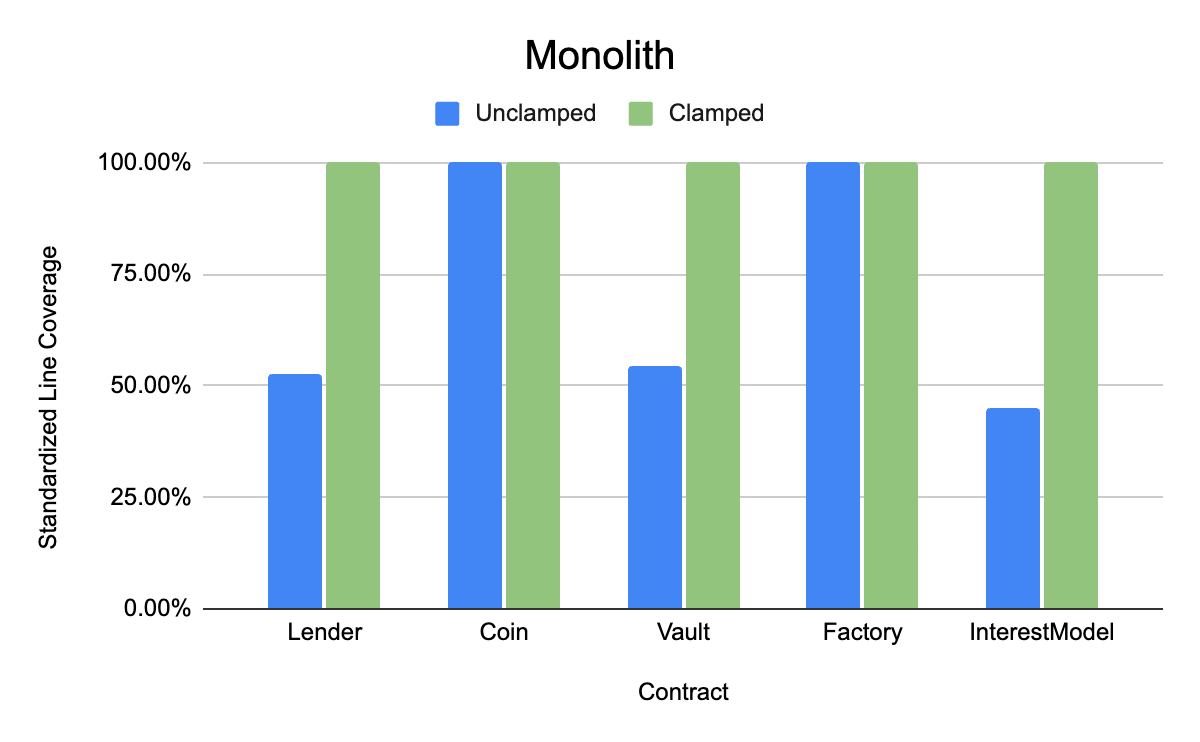
Monolith (core targeted contracts are Lender, Coin, Vault, Factory, InterestModel)
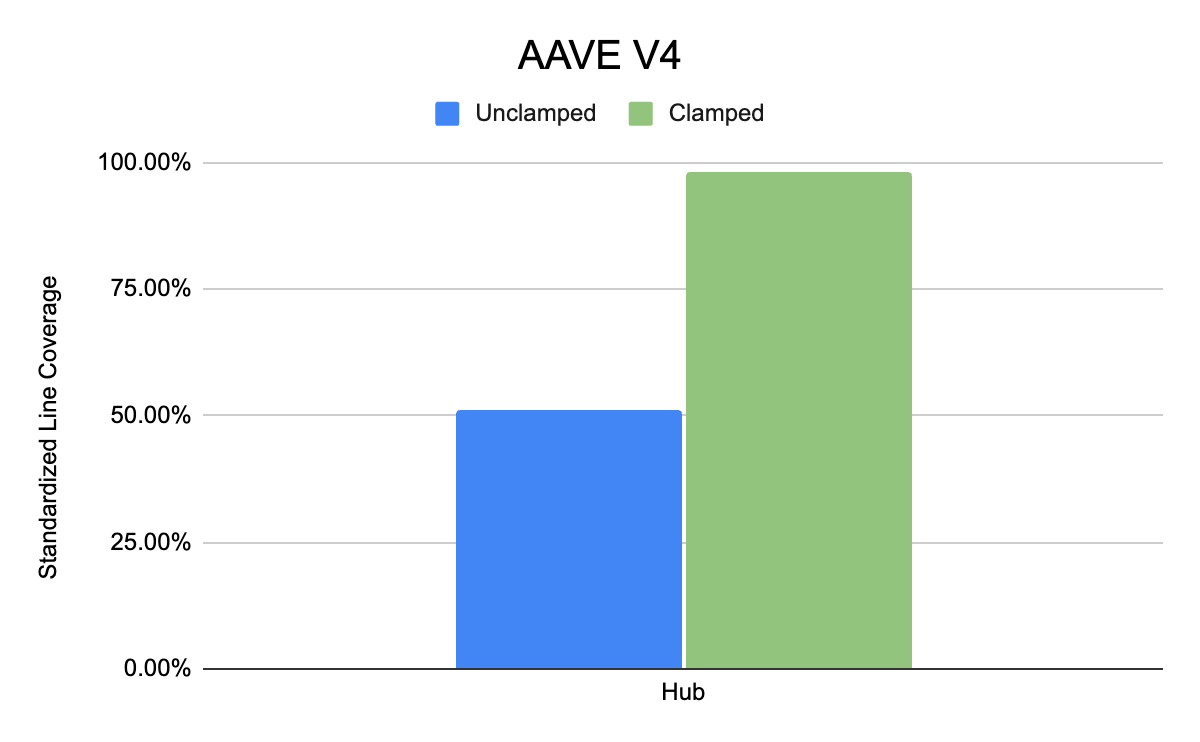
AAVE V4 (core targeted contract is Hub)
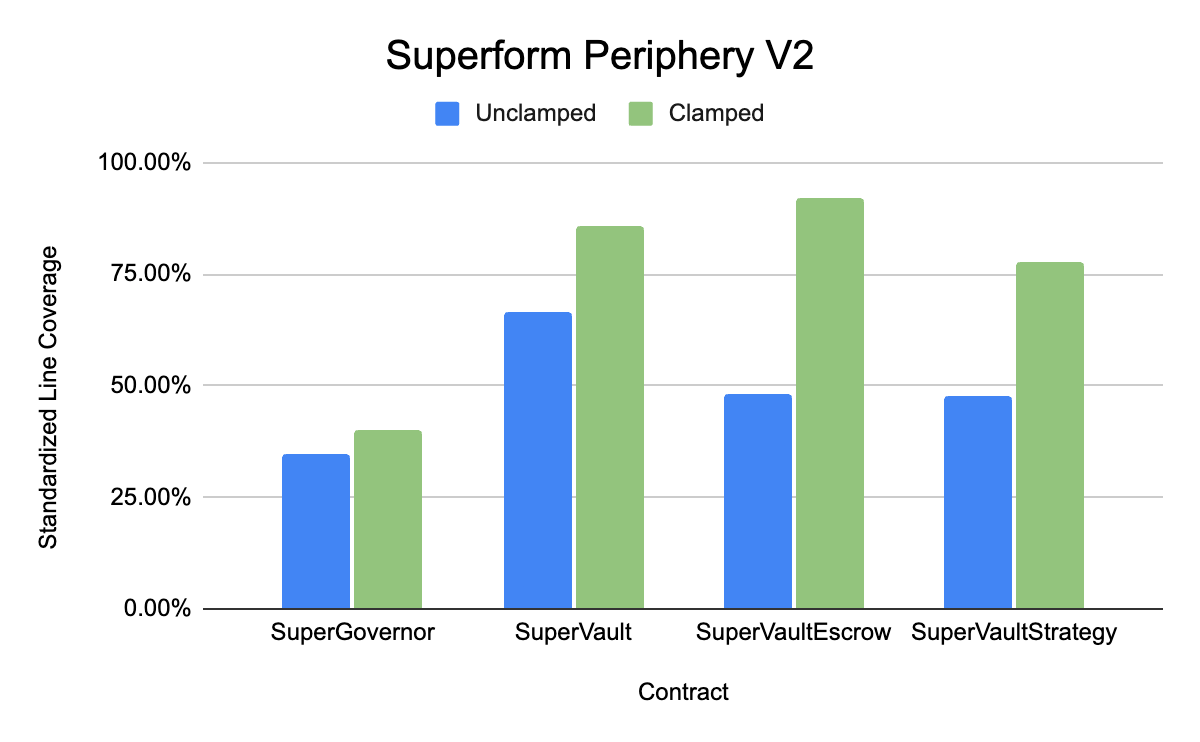
Superform Periphery (core targeted contracts are SuperGovernor, SuperVault, SuperVaultEscrow and SuperVaultStrategy)
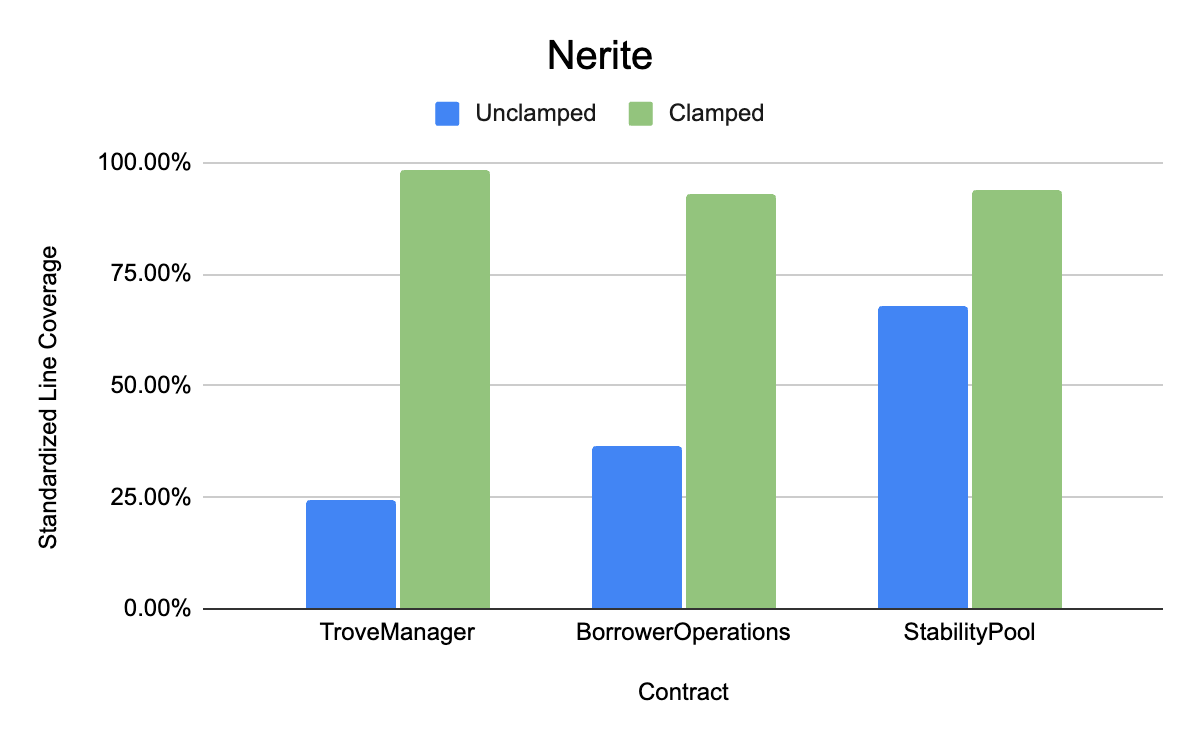
Nerite (core targeted contracts are BorrowerOperations, StabilityPool and TroveManager)
Unresolved Edge Cases
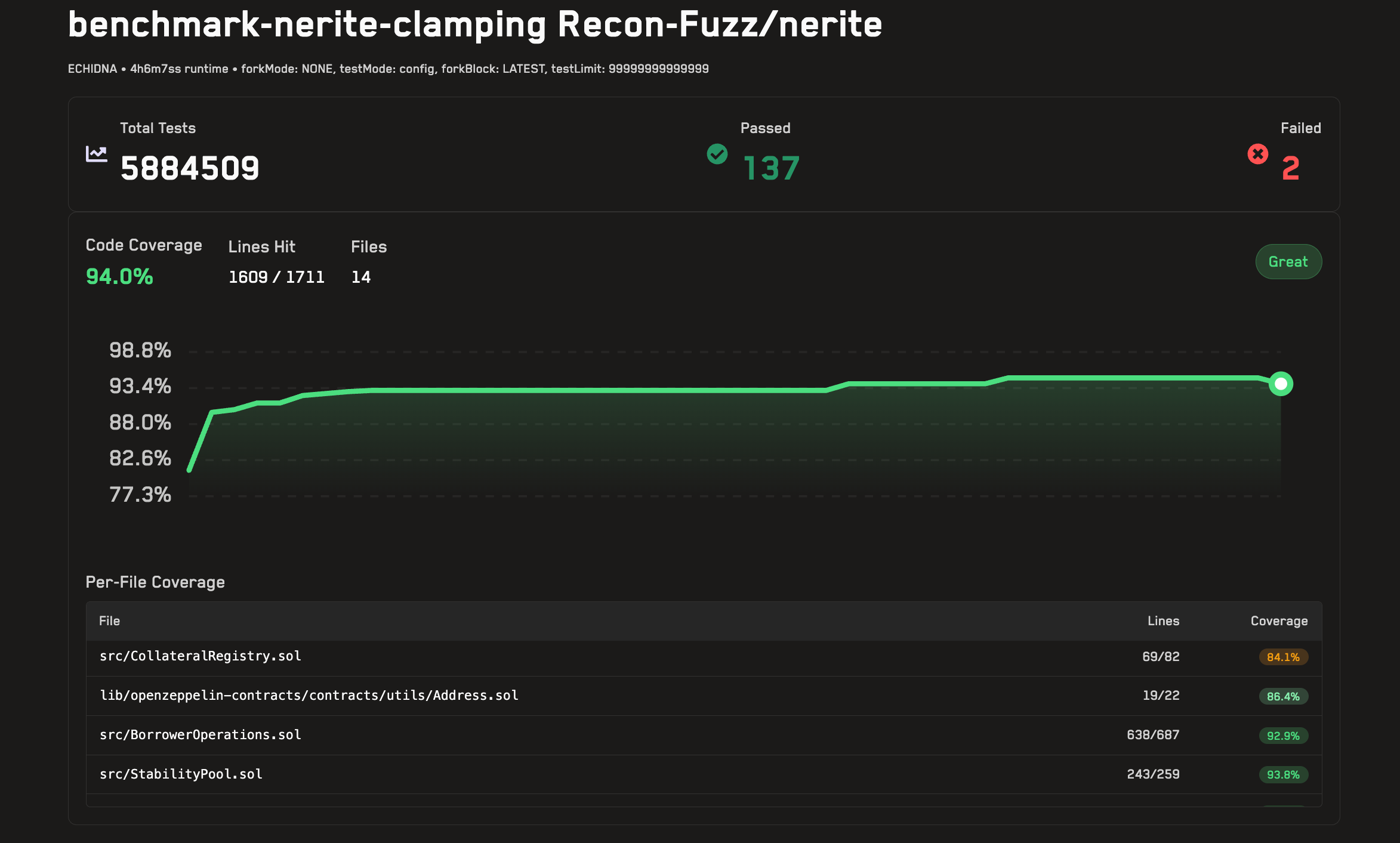
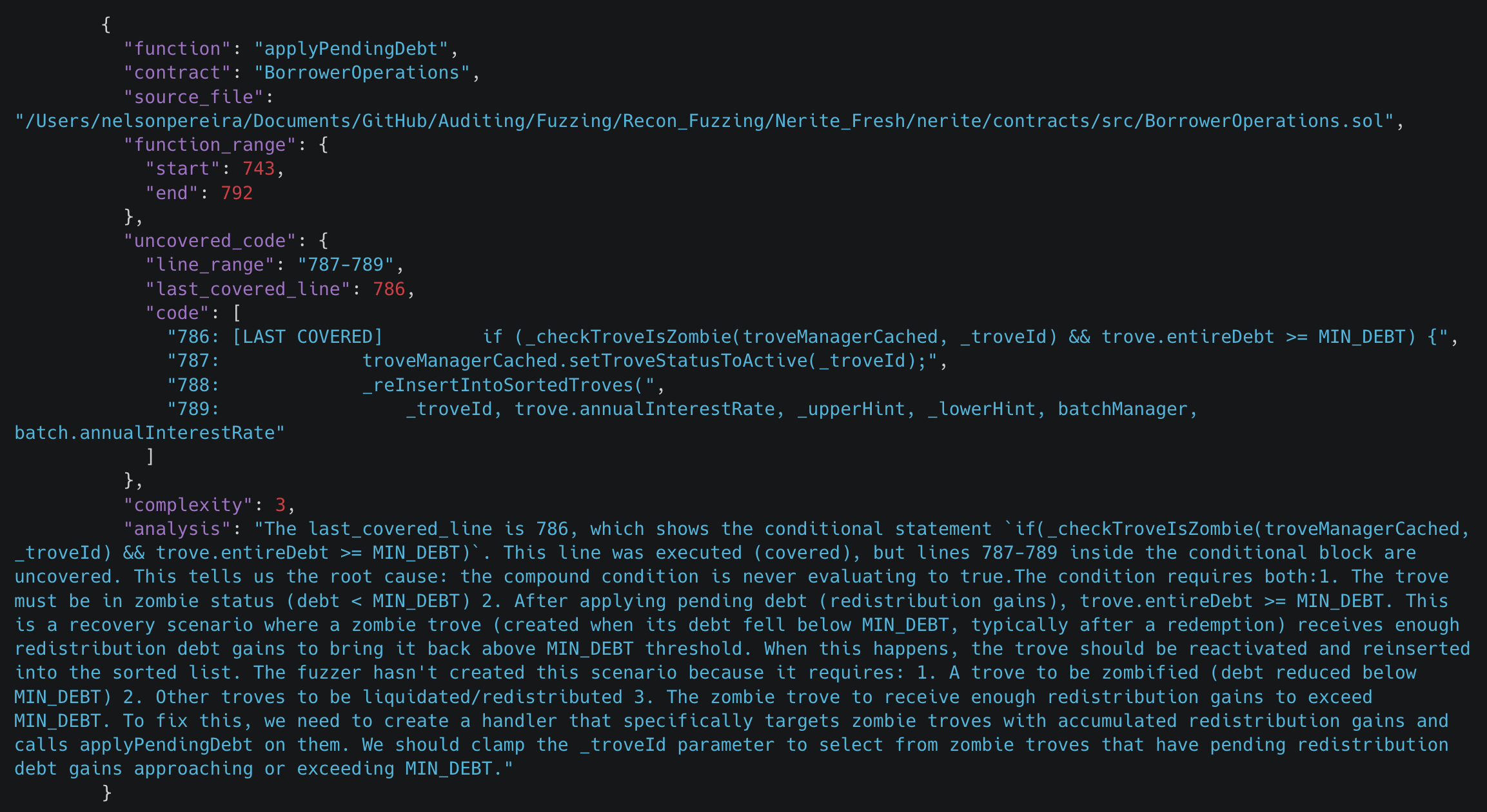
It should be noted that for Nerite, high coverage was reached but there were still important edge cases that were uncovered even after the workflow was run and made iterative attempts to try to cover it. This is a clear area that needs improvement which we are working on.
Our temporary solution for such cases identifies the source of the issue and provides it in an easy to understand format which can be used by a human in the loop to quickly implement a fix to cover the remaining uncovered lines.
Coverage Results
As can be seen from the above benchmarks, the experimental group where clamping and shortcuts were applied by the workflow consistently achieved higher line coverage in the given time than the unclamped cases. We believe that given this and the significant reduction in time to implement the clamped handlers, these benchmarks demonstrate a compelling case for using Recon Magic to achieve full standardized line coverage.
Additionally, because the approach taken by the agent only creates clamped handlers and shortcuts while leaving unclamped handlers unchanged, there is no known downside to running the agent as in the worst case scenario it would simply implement clamped handlers that are ineffective but wouldn’t reduce the reachable search space of the fuzzer.
Reproducibility
The non-deterministic nature of AI agents implies that no two runs of the workflow will output the exact same clamped handlers. We have, however, provided additional tools and segmentation of the problem in the workflow that make it significantly more likely to create outputs that are consistent with our best practices so that while no two implementations may be exactly the same, they are still effective at improving coverage.
The workflow also commits changes at certain predefined steps. This allows confirming what changes were implemented for a given step of the workflow making it easier to understand and evaluate the reasoning of the agent for a particular step.
While there is no way for us to prove that the AI implemented all the clamping changes in the benchmark repositories, we attest that this is the case. We further encourage anyone wishing to replicate our results to use the Recon Magic “coverage V2” workflow on the default setup repos here and subsequently run the fuzzer to evaluate the coverage on the clamped and unclamped setups.
Proof of the coverage results for the benchmark repositories can be found by using the provided links to the Recon Pro results page from the Results section under each graph. The standardized line coverage is calculated using the call tree of the targeted functions of interest and displayed on the job’s page.
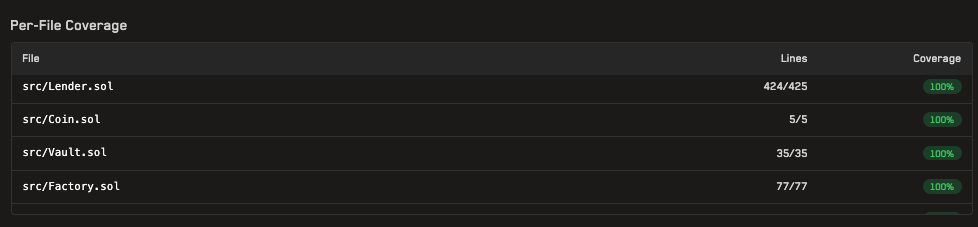
The standardized line coverage value will differ from the value displayed in the coverage report as it is calculated using only the functions of interest whereas the value in the report is calculated using all functions defined in the contract.
Future Work
We’ve seen above how using standardized line coverage gives us a clearer picture of what we actually care about covering in a fuzzing campaign. We then saw how using standardized line coverage as an optimization function allowed us to create an agentic workflow that achieves high coverage over any project.
Line coverage, however, has many flaws, namely an inability to effectively judge coverage over specific combinations of conditions. However, the current tools for invariant testing use it as the primary metric for fuzzer efficacy, leading to our decision to use standardized line coverage as the primary metric for this benchmark.
A more nuanced coverage metric based on non-reverting inputs to functions and their possible combinations (we call these coverage classes) would allow for better evaluation of the covered states out of all possible states.
This metric could then be improved by using mutation testing to evaluate the sensitivity of the runs. This would modify the changes implemented by the agent to determine if they were actually directly responsible for the increase in the output coverage.
Recon Magic Launch
Recon Magic is in private beta testing and will soon be in public beta, at which point we'll release 50 invites code.
If you’d like to be amongst the first to try out Recon Magic when it launches, join our Discord channel.
What’s really interesting here isn’t just the 38× speedup, but the choice of standardized line coverage as the objective function.
You’re effectively telling the agent what “progress” means in a way that aligns with real system state exploration, not just surface-level execution.
This feels like a broader pattern: once agents optimize against semantic coverage instead of raw metrics, they stop behaving like prompt generators and start behaving like search systems.